
| What happens during a backup |
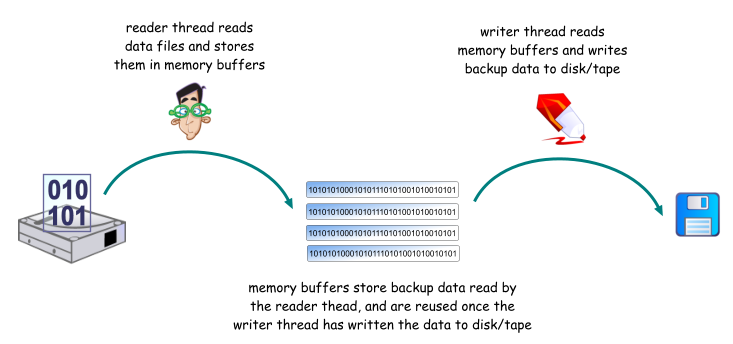
During a backup, SQL Server creates one reader thread for each
volume that the database files reside on. The reader thread
simply reads the contents of the files. Each time that it
reads a portion of the file, it stores them in a buffer.
There are multiple buffers in use, so the reader thread will
keep on reading as long as there are free buffers to write to.
SQL Server also creates one writer thread for each backup
device to write the contents of the buffers out to disk or tape.
The writer thread writes the data from the buffer to the disk
or tape. Once the data has been written, the buffer can be
reused by the reader thread.
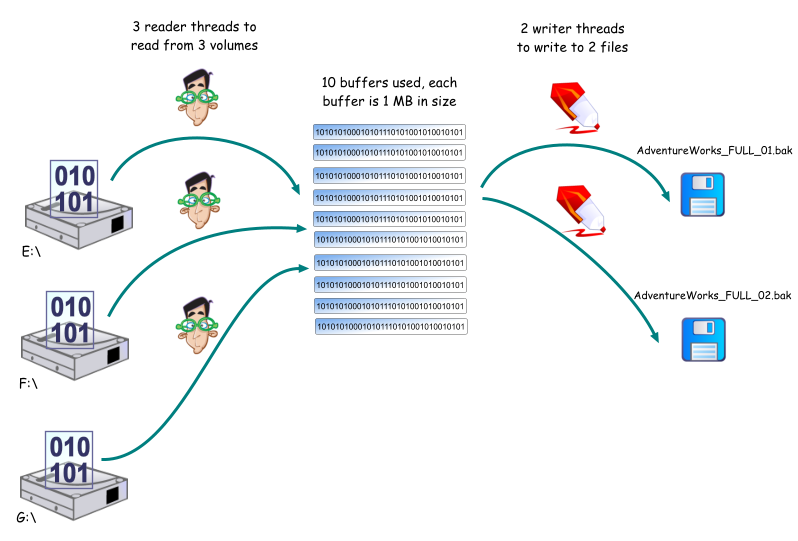
Thus, given the following command:
BACKUP DATABASE AdventureWorks TO
DISK =
'M:\backups\AdventureWorks_FULL_01.bak',
DISK =
'N:\backups\AdventureWorks_FULL_02.bak'
WITH BUFFERCOUNT = 10, MAXTRANSFERSIZE = 1048576 |
and assuming that AdventureWorks files are spread across three
volumes, the backup process will proceed as follows:
 |
| SQL Server does not distinguish between logical and
physical volumes. In the above example, if E:\, F:\ and G:\
are all partitions on the same physical drive, 3 reader threads are
still used to read the data files. If your disk cannot keep
up with the read demands, the backup throughput will be adversely
affected. |
| |
If the BUFFERCOUNT and
MAXTRANSFERSIZE parameters are
not used, SQL Server will dynamically determine the number of
buffers to use and the size of each buffer. The total memory
used for the backup buffers will be BUFFERCOUNT x MAXTRANSFERSIZE (bytes) + some overheads.
This memory is allocated from the non-buffer pool
memory, also known as the MemToLeave memory. If you specify
values that are larger than what is available, SQL Server will
raise the following error:
Server: Msg 701, Level 17, State 1, Line 1
There is insufficient system memory to run this query.
Server: Msg 3013, Level 16, State 1, Line 1
BACKUP DATABASE is terminating abnormally. |
If you want to find out the size and quantity of the buffers
used by SQL Server for a backup, you can turn on trace flags 3605
and 3213. The values used are then recorded in the SQL Server
log e.g.
2008-07-14 17:21:20.65 spid51
BufferPoolLimit: 100 MB
2008-07-14 17:21:20.65 spid51 Backup/Restore buffer
configuration parameters
2008-07-14 17:21:20.65 spid51 Buffer count:
15
2008-07-14 17:21:20.65 spid51 Max transfer size:
983040
2008-07-14 17:21:20.65 spid51 Total buffer space:
14 MB
2008-07-14 17:21:20.65 spid51 Buffers per read
stream: 15
2008-07-14 17:21:20.65 spid51 Buffers per write
stream: 5
2008-07-14 17:21:20.65 spid51 Memory Limit:
100 MB
|
 Acknowledgement: Some icons
on this page were generously provided by Fasticon.com.
Acknowledgement: Some icons
on this page were generously provided by Fasticon.com.
Document history
| 7/31/2008 | Added note on logical volumes. |
| 7/14/2008 | Added details on trace flags 3605 and 3213. |
| 7/11/2008 | Initial release. |




