|
 |
 |
| Speeding up backups |
| |
|
||||||||||||||||
|
|

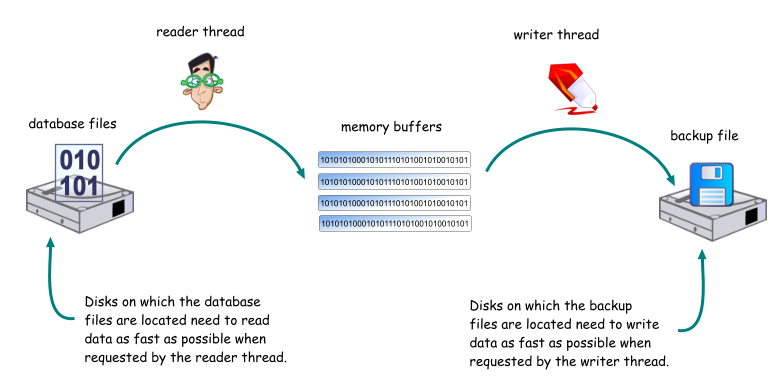
For a full database backup, the speed of the backup process depends largely on 2 elements: the read throughput of the disks where the data and log files are located, and the write throughput of the disks where the data are being written to.
The read throughput depends on the overall read speed of the disks where the database files are located. Hence, it will be different for each database if the database files for each database is located on different sets of disks. One way to measure the read throughput is to start a full database backup, and monitor the Read bytes/sec performance counter for the disks where the database files are located, using the Windows Performance Monitor. The backup file should be located on a physically different disk from the database files, otherwise the measurement will be inaccurate. Also, there should be little other read activity on those disks e.g. from other applications or the operating system itself.
Assuming that the database files are all about equal in size, the lowest measurement you obtain will be the maximum backup throughput you could expect from your system for that particular database. Another way to measure read throughput is to perform a backup to a NUL device e.g.
Note that we used the COPY_ONLY option, so this can only be ran on a SQL Server 2005 instance. You can perform the same backup on a SQL Server 2000 instance by omitting the COPY_ONLY option, but BE VERY CAREFUL. A backup to a NUL device is recognised as a valid backup. This means that if you perform a full backup to a NUL device, any differential backups you make after that are useless unless you perform a full database backup after the NUL backup. If you perform a transaction log backup to a NUL device, you would have broken your log restore chain, rendering future transaction log backups useless. If you must perform a NUL backup on a SQL Server 2000 instance, do take the necessary steps after that to ensure that your disaster recovery goals can still be met. Great, I measured my read throughput for AdventureWorks to be 46 MB/sec. This means that 46 MB/sec is the maximum backup throughput I can hope for, since that's the fastest that my disks can provide the data to the SQL Server backup reader thread(s). So how can I improve this? Using faster disks would be one way. Another way would be to spread the database files across multiple physical disks, so that more reader threads are created to read the data simultaneously. Reducing the file fragmentation level of the database files will also improve the throughput, especially when the database files are heavily fragmented.
Now for the write throughput. Run a backup to a file. On my system, I got the following result:
Well, it appears that the write throughput is the bottleneck here. My disks can provide data at 46 MB/sec, but only write at a rate of 18.688 MB/sec. Actually, I was backing up to the same disk where the data files were located. When I backed up to a file on a different physical disk, I got the following result:
Much better. Since the read and writes are now happening on independent disks, the overall throughput has improved significantly. That's one way of improving write throughput. Another way is to spread the backup across multiple files. If your disks can handle it, the files could be located on the same physical disk. If not, you'll be better off locating the files on physically different disks. Faster disks to store the backup files will be another obvious choice. However, take a step back first and look at the overall picture. Remember that the backup throughput is first and foremost constrained by your read throughput. It doesn't matter if my disks can write at a rate of 150 MB/sec. If my read throughput is only 46 MB/sec, that's the maximum backup throughput I can ever attain.
So to recap what I've done: ·I measured my read throughput. 46 MB/sec. We discussed ways of improving this: ·using faster disks ·relocating the database files across physically different disks ·reducing the file fragmentation level of the database files ·I ran a backup to a file on the same disk where the database files were located. Backup throughput: 18 MB/sec. Bad. We know that read throughput is 46 MB/sec, so we should aim for a backup throughput closer to that. I then backed up to a file on a physically different disk from where the database files were located. Backup throughput: 43 MB/sec. Much better. Can we improve this further? Unlikely. But if our write throughput only 25 MB/sec, we could consider the following options: ·use faster disks for the backup files ·spread the backup across multiple files (on the same or physically different disks, depending on disk throughputs) ·use a backup compression tool. If the compression rate is good, less data is written to disk, resulting in faster write throughput. This comes at a cost of increased CPU utilization to perform the compression.
There sure was a lot of things that could've been done right at the beginning when the database was first created in order to ensure that we get the best possible backup throughput. Actually, the same considerations apply when you want to obtain the best possible performance for your database. ·Disk speed Using the fastest possible disks or disk configuration your budget allows help in improving the backup throughput.
·Database files Spreading the database files across multiple physical disks allows SQL Server to use multiple reader threads to read from each disk. This shortens the time taken to read the data completely, when compared to storing the database in a single data file.
·Really use physically different disks SQL Server creates reader threads based on the number of logical volumes that your database files resides on. However, if all your volumns are partitioned on the same physical disk, your backup throughput will suffer if your disk cannot keep up with the read demands of the reader threads.
·File fragmentation Creating the database files with an initial size equal to the expected maximum size of the database reduces file fragmentation. If the database files are set to auto-grow, setting a large growth increment will also help to reduce fragmentation.
·Plan to store your transaction logs on independent disks Storing your transaction log files on disks that are physically independent of the database files, or even the operating system and other applications that are I/O intensive, help in improving the read write throughput when performing transaction log backups. Disk I/O operations on transaction logs are serial in nature, while disk I/O operations on data files are random. Placing transaction log files on the same disks as data files slows down transaction log backups when the database is busy.
·Plan to store backups on independent disks Storing your backup files on disks that are physically independent of the database files, or even the operating system and other applications that are I/O intensive, help in improving the backup write throughput.
Document history
|
|||||||||||||||